Analyzing Source Code Using Neural Networks: A Case Study
Code smells indicate the presence of quality issues in source code. An excessive number of smells make a software system hard to evolve and maintain. In this article, we apply deep learning models based on CNN and RNN to detect code smells without extensive feature engineering, just by feeding the source code in tokenized form.
This article is derived from our paper “On the Feasibility of Transfer-learning Code Smells using Deep Learning” by Tushar Sharma, Vasiliki Efstathiou, Panos Louridas, and Diomidis Spinellis.
Overview
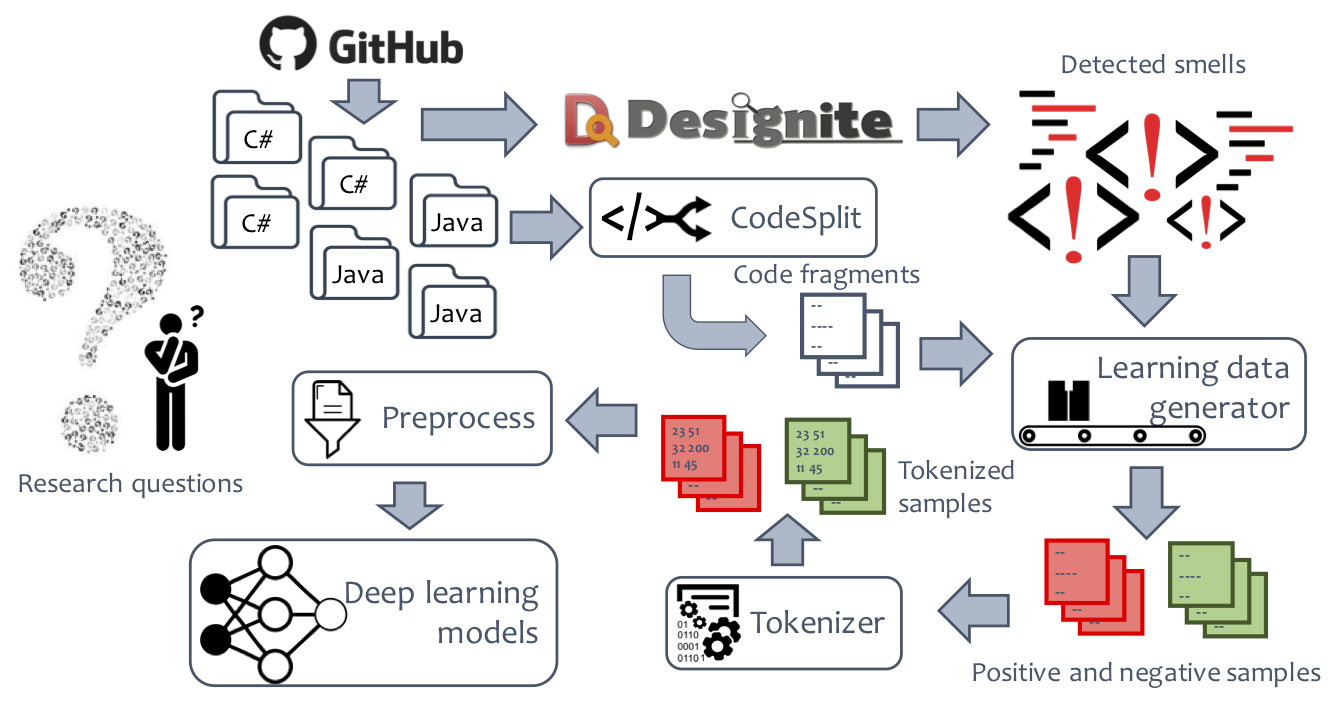
Above figure provides an overview of the setup. We download 1,072 C# repositories from GitHub. We use Designite to analyze C# code. We use CodeSplit to extract each method and class definition into separate files from C# programs. Then the learning data generator uses the detected smells to bifurcate code fragments into positive or negative samples for a smell—positive samples contain the smell while the negative samples are free from that smell. Tokenizer takes a method or class definition and generates integer tokens for each token in the source code. We apply preprocessing operation, specifically duplicates removal, on the output of Tokenizer. The processed output of Tokenizer is ready to feed to the neural networks.
Data curation
Implementation of all the data curation steps can be found on GitHub.
Downloading repositories
We download repositories containing C# code from GitHub. We use RepoReapers dataset to filter out low-quality repositories.
Smell Detection
We use Designite to detect smells in C# code. Designite is a software design quality assessment tool for code written in C#. It supports detection of eleven implementation, 19 design, and seven architecture smells. It also provides commonly used code metrics and other features such as trend analysis, code clone detection, and dependency structure matrix to help developers assess the software quality. A free academic license of Designite can be requested.
Splitting Code Fragments
CodeSplit is a utility programs that split methods or classes written in C# source code into individual files. Hence, given a C# project, the utility can parse the code correctly using Roslyn and emit the individual method or class fragments into separate files following hierarchical structure (i.e., namespaces becomes folders).
Generating Training and Evaluation Data
The learning data generator requires information from two sources-a list of detected smells for each analyzed repository and a path to the folder where the code fragments corresponding to the repository are stored. The program takes a method (or class in case of design smells) at a time and checks whether the given smell has been detected in the method (or class) by Designite. If the method (or class) suffers from the smell, the program puts the code fragment into a “positive” folder corresponding to the smell otherwise into a “negative” folder.
Tokenizing Learning Data
Machine learning algorithms require the inputs to be given in a representation appropriate for extracting the features of interest, given the problem in hand. For a multitude of machine learning tasks it is a common practice to convert data into numerical representations before feeding them to a machine learning algorithm. In the context of this study, we need to convert source code into vectors of numbers honoring the language keywords and other semantics. Tokenizer is an open-source tool that provides, among others, functionality for tokenizing source code elements into integers where different ranges of integers map to different types of elements in source code. Currently, it supports six programming languages, including C# and Java.
Data Preparation
We split the samples in the ratio of 70–30 for training; i.e., 70% of the samples are used for training a model while 30% samples are used for evaluation. We limit the maximum number of positive/negative training samples to 5,000. Therefore, for instance, if negative samples are more than 5,000, we drop the rest of the samples. We perform model training using balanced samples, i.e., we balance the number of samples for training by choosing the smaller number from the positive and negative sample count; we discard the remaining training samples from the larger side. An examples of the above described mechanism is shown in the following figure.

Selection of Smells
We chose complex method (CM— i.e., the method has high cyclomatic complexity), magic number (MN— i.e., an unexplained numeric literal is used in an expression), and empty catch block (ECB— i.e., a catch block of an exception is empty). To expand the horizon of the experiment, we also select multifaceted abstraction (MA— i.e., a class has more than one responsibility assigned to it) design smell. If you would like to know more about smells and their different types, here is a catalog of smells.
Architecture of Deep Learning Models
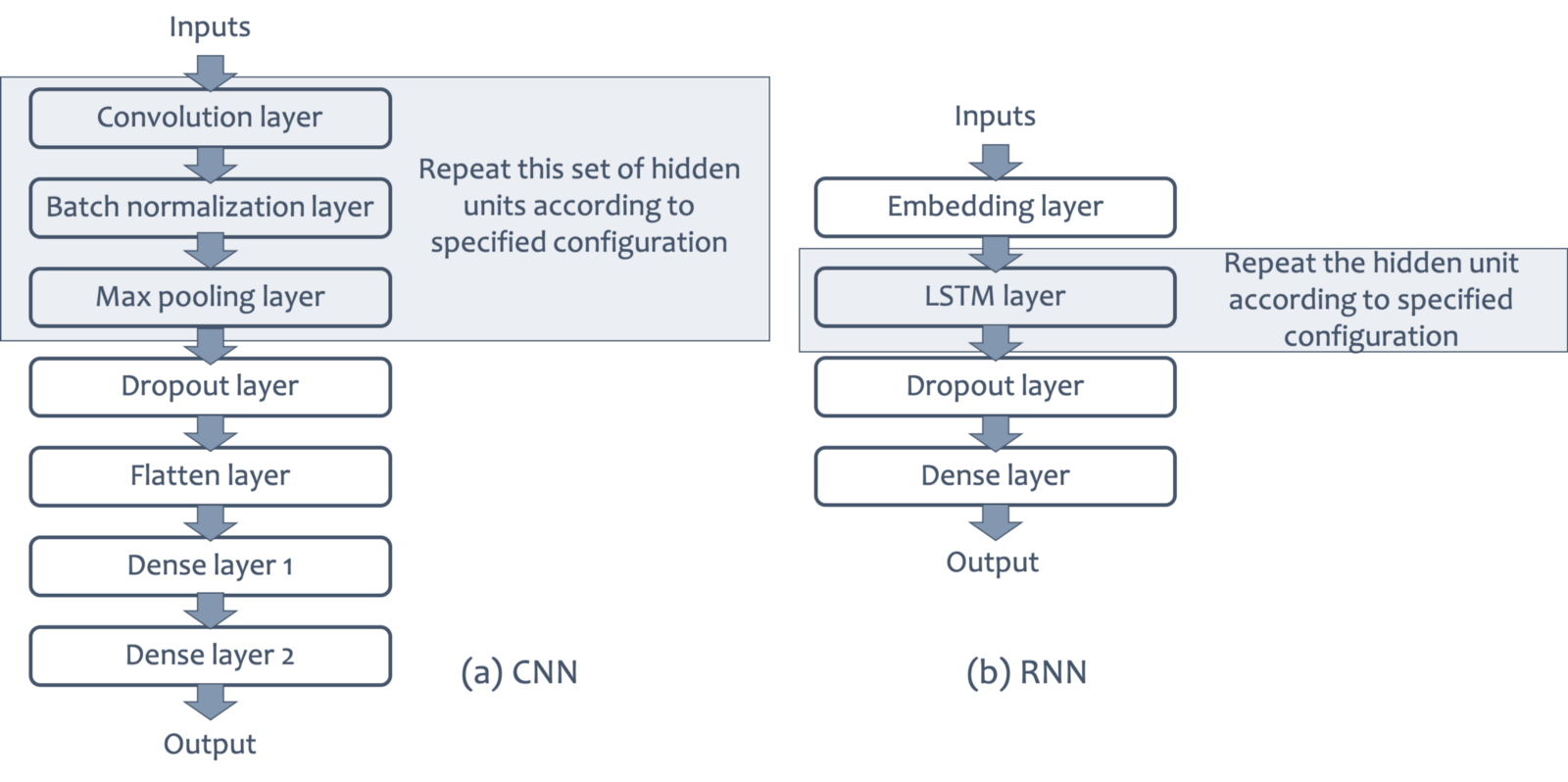
The implementation of above-mentioned CNN architecture is given below in python using Keras.
Along with RNN, we experiment with 1D and 2D variants of CNN; hence, we experiment and report three deep learning models (CNN-1D, CNN-2D, and RNN).
We use dynamic batch size depending upon the size of samples to train. We divide the training sample size by 512 and use the result as the index to choose one of the items in the possible batch size array (32, 64, 128, 256). For instance, we use 32 as batch size when the training sample size is 500 and 256 when the training sample size is 2000.
We ensure the best attainable performance and avoid over-fitting by using early stopping as a regularization method (with maximum epochs = 50 and patience = 5). It implies that the model may reach a maximum of 50 epochs during training. However, if there is no improvement in the validation loss of the trained model for five consecutive epochs, the training is interrupted. Along with it, we also use model check point to restore the best weights of the trained model.
Similarly, the employed RNN implementation of the above architecture is given below.
The complete implementation can be found on GitHub.
Results
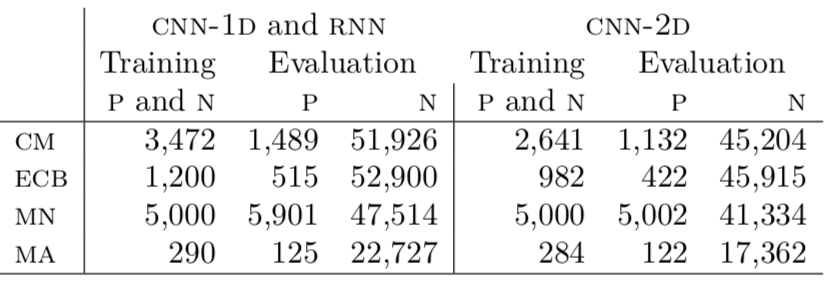
Table 1 presents the number of positive and negative samples used for each smell for training and evaluation. We train our models with the same number of positive and negative samples; however, the evaluation sample is realistic i.e., we retain all the positive and negative samples obtained from the data curation process.
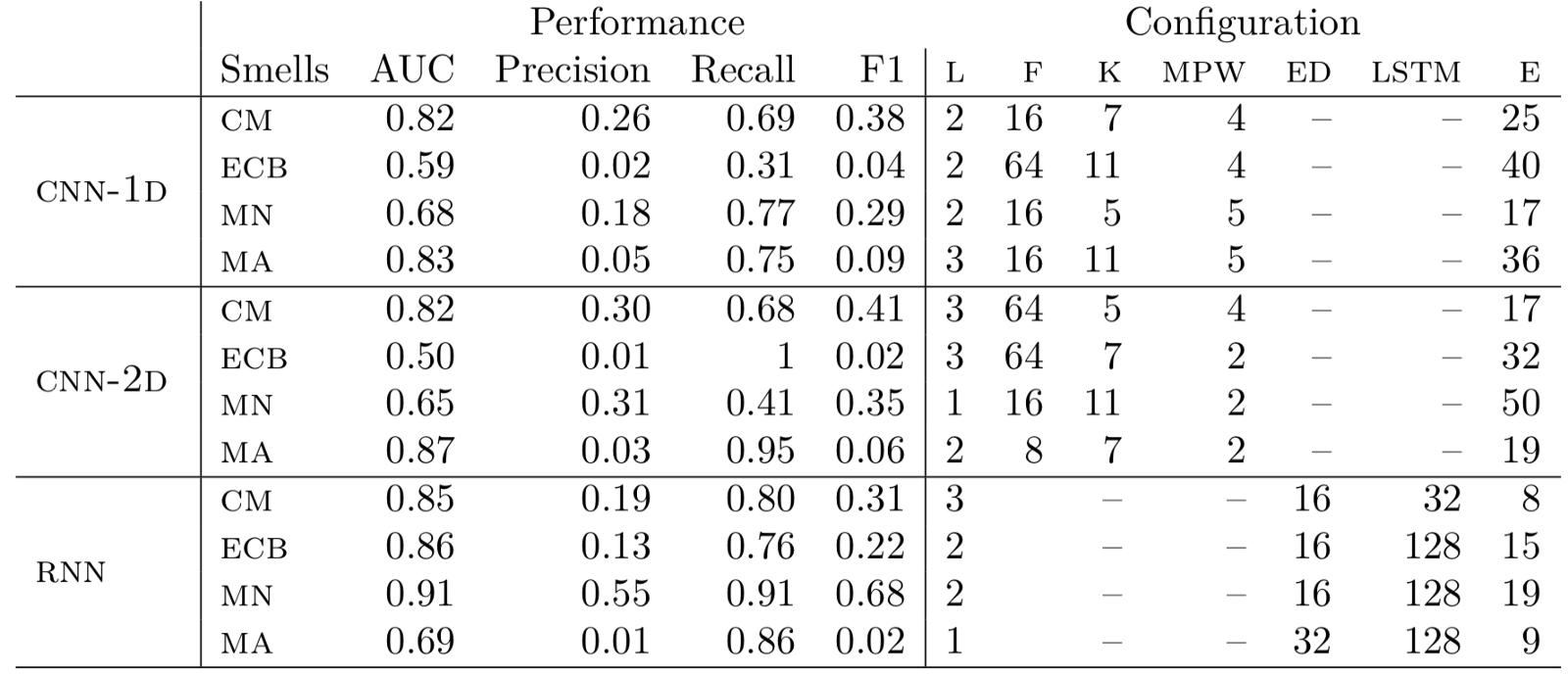
Following table lists performance metrics (AUC, precision, recall, and F1) for the optimal configuration for each smell, comparing all three deep learning models. It also lists the hyper-parameters associated with the optimal configuration for each smell.
Following figure presents the performance (F1) of the deep learning models corresponding to each smell considered in this exploration.
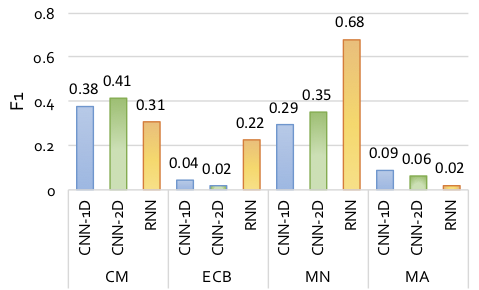
For complex method smell, CNN-2D performs the best; though, performance of CNN-1D is comparable. This could be an implication of the fact that the smell is exhibited through the structure of a method; hence, CNN models, in this case, could identify the related structural features for classifying the smells correctly. On the other hand, CNN models perform significantly poorer than RNN in identifying empty catch block smells. The smell is characterized by a micro-structure where catch block of a try-catch statement is empty. RNN model identifies the sequence of tokens (i.e., opening and closing braces), following the tokens of a try block, whereas CNN models fail to achieve that and thus RNN performs significantly better than the CNN models. Also, the RNN model performs remarkably better than CNN models for magic number smell. The smell is characterized by a specific range of tokens and the RNN does well in spotting them. Multifaceted abstraction is a non-trivial smell that requires analysis of method interactions to observe incohesiveness of a class. None of the employed deep learning models could capture the complex characteristics of the smell, implying that the token–level representation of the data may not be appropriate for capturing higher–level features required for detecting the smell. It is evident from the above discussion that all the employed models are capable of detecting smells in general; however, their smell-specific performances differ significantly.
Conclusion
We observe that deep learning methods can be used for smell detection with mere tokenized source code. Specifically, we found that CNN and RNN deep learning models can be used for code smell detection, specifically for implementation smells, though with varying performance.
Relevant links
- Source code and data
- Designite— Smell detection tool
- CodeSplit
- Tokenizer
- My FOSDEM talk - Smelling source code using deep learning

